Процесс чтения текста является обратным процессу письма, когда письменный текст преобразуется в устную речь. Чтение — это не что иное, как декодирование письменного текста.
Кодирование строк
Для того чтобы компьютер мог представить передаваемые ему символы, они должны быть в определенной кодировке. Вы можете читать книгу в текстовом процессоре, и вместо слов вы получите кучу вопросительных знаков. Причина в том, что процесс декодирования текста происходит неправильно (если говорить совсем просто, программа пытается показать американцу букву «Z», например, перебирая английский алфавит).
Возникают следующие вопросы: Что происходит, кто виноват? Ответ не будет коротким.
Компьютер – человек
Компьютерные технологии, в конце концов, работают с единицами и нулями. На клавиатуре имеется не менее 100 клавиш. Все, что вы вводите, в конечном итоге преобразуется в одни и те же двоичные значения.
В этом и заключается суть кодирования. Компьютер хранит все буквы, цифры и символы в виде определенного значения единиц и нулей. Например: английская буква «Y» в двоичном коде выглядит как «0b1011001». Английская буква «N» выглядит как «0x59» в английской системе счисления и «0x59» в шестнадцатеричной системе.
Для осмысленного диалога между пользователем и компьютером необходим двусторонний интерпретатор: — «человеческие» строки должны быть преобразованы в байты; — «компьютерный» язык должен быть преобразован в осмысленные структуры, понятные пользователю.
В Python за это отвечают функции кодирования/декодирования. Важно, чтобы сообщение было закодировано и декодировано с помощью одной и той же кодировки, чтобы избежать проблемы бессмысленных наборов символов.
ASCII
Ранние компьютеры имели небольшую емкость, поэтому 7 бит (или 128 символов) было достаточно для представления необходимого количества символов. Он включал весь английский алфавит в верхнем и нижнем регистре, цифры, символы и вспомогательные знаки.

Поначалу этого было достаточно. Кодировка называлась ASCII (произносится как «аски» или «эски»). В Python и сегодня можно искать символы ASCII. Для этого существует встроенный строковый модуль.
import string print(string.ascii_letters) print(string.digits) print(string.punctuation) code result abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ 0123456789 !"#$%&'()*+,-./:?@\^_`<|>~Другие свойства модуля вы можете прочитать самостоятельно.
Время шло, общество становилось все более электронным, 128 символов было уже недостаточно. Последние 8 бит, которые остались, также использовались для кодирования (а это означает 128 символов). В результате появилось множество кодировок (кириллица, немецкая и т.д.). Эта ситуация привела к проблемам. Уже тогда англичанин, получающий электронное письмо из России, видел не русские буквы, а набор непонятных ломаных букв.
Коды должны были быть указаны в названиях документов.
14.1. Кодировка ASCII и её расширения
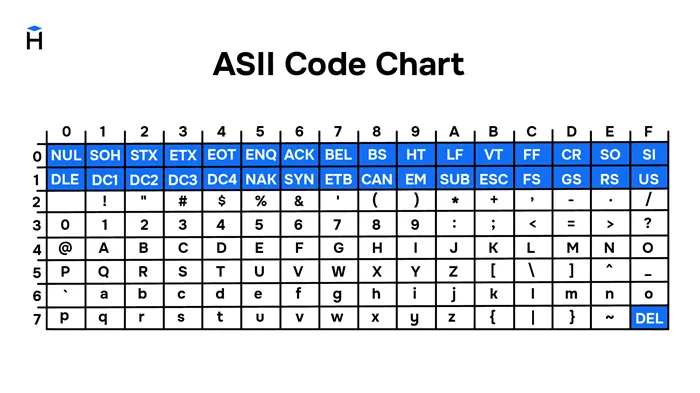
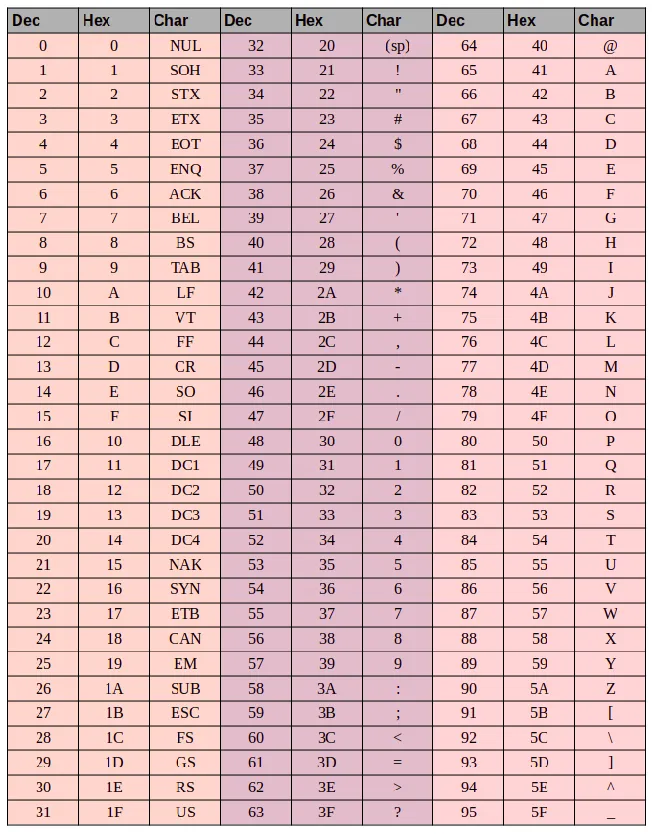
Основой для стандартов кодирования компьютерных символов является ASCII (American Standard Code for Information Interchange) — американский стандартный код для обмена информацией, разработанный в США в 1960-х годах и используемый для всех видов связи (телеграф, факс и т.д.), включая некомпьютерные. Это 7-битный код: Общее количество символов равно 2 7 = 128, из которых первые 32 символа являются управляющими, а остальные — представляемыми, т.е. имеющими графическое представление. Воспроизводимые символы ASCII включают буквы латинского алфавита (верхний и нижний регистр), цифры, знаки препинания и цифровые символы, скобки и некоторые специальные символы. Кодировка ASCII показана в таблице 3.8.
Таблица 3.8
Кодировка ASCII
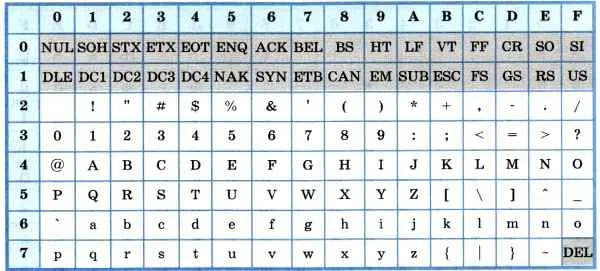
Хотя для кодирования символов в ASCII достаточно 7 бит, каждому символу в памяти компьютера отводится ровно 1 байт (8 бит), при этом код символа размещается в младших значащих битах, а старший бит равен 0.
Например, 01000001 — это код для латинской заглавной буквы «A», и в шестнадцатеричных цифрах он может быть записан как 41.
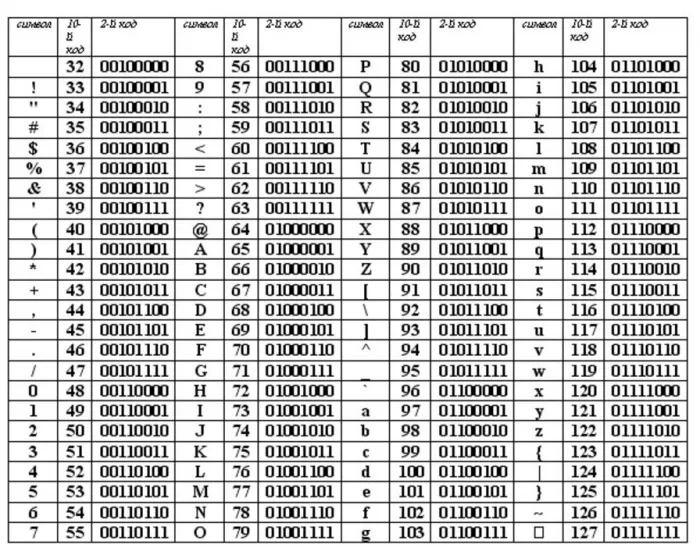
Стандарт ASCII был разработан для использования только с английским текстом. Со временем возникла необходимость кодировать и неанглийские буквы. Многие страны начали разрабатывать для этой цели расширения ASCII, используя однобайтовые коды символов. Первые 128 символов кодовой таблицы были идентичны коду ASCII, а остальные (от 128 до 255) использовались для кодирования букв национального алфавита, символов национальной валюты и т.д. Из-за непоследовательности этих разработок было создано множество версий табличных кодов для многих языков (например, для русского языка было создано около десятка!).
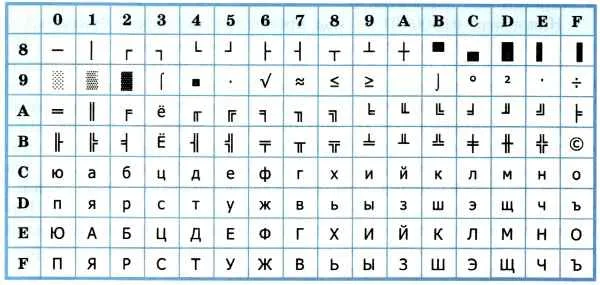
Впоследствии использование кодовых слов было несколько упорядочено: каждому кодовому слову было присвоено определенное название и номер. Для русского языка наибольшее распространение получили таблицы однобайтовых кодовых слов CP-866, Windows-1251 (таблица 3.9) и KOI-8 (таблица 3.10). В них первые 128 символов такие же, как и в кодировке ASCII, а русские буквы размещены во второй части таблицы. Обратите внимание, что коды русских букв в этих кодировках разные.
Таблица 3.9
Кодировка Windows 1251
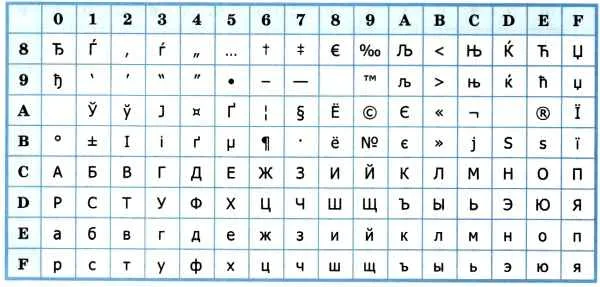
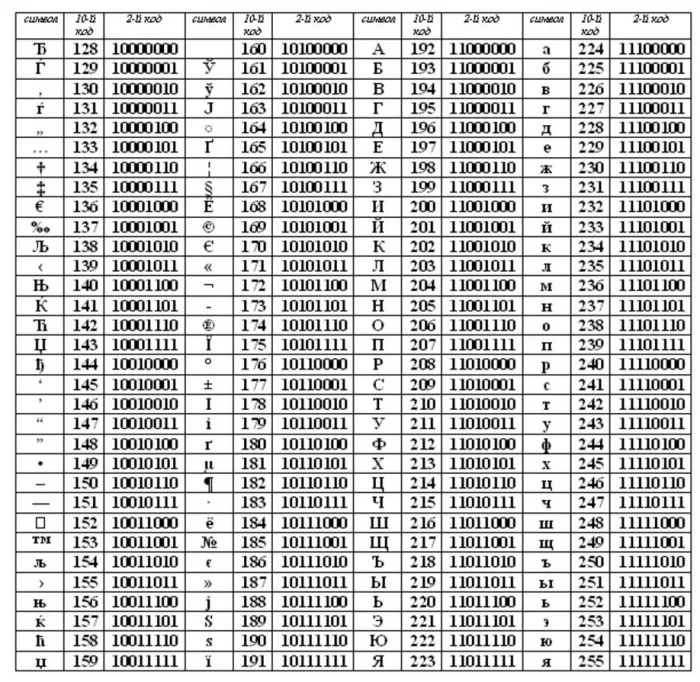
Таблица 3.10
Кодирование КОИ-8
Мы выяснили, что при нажатии буквенно-цифровой клавиши в компьютер отправляется строка из нулей и единиц. В текстовых файлах хранятся не изображения символов, а их коды.
При выводе текста на монитор или принтер необходимо получить изображение всех символов, составляющих текст, и эти изображения могут быть разнообразными и весьма причудливыми. Внешний вид отображаемых символов кодируется и хранится в специальных файлах шрифтов. Современные текстовые процессоры могут встраивать шрифты в файл. В этом случае файл содержит не только коды символов, но и описание шрифтов, использованных в документе. Кроме того, файлы, созданные с помощью текстовых редакторов, содержат информацию о форматировании текста, такую как размер, путь, поля, отступы, межстрочный интервал и другую дополнительную информацию.
14.2. Стандарт Unicode
Ограничения 8-битной кодировки, которая не позволяла одновременно использовать несколько языков, и сложность преобразования одной кодировки в другую привели к разработке нового кода. В 1991 году был разработан новый стандарт кодирования символов под названием Unicode, который позволяет использовать в текстах все символы всех языков мира.
Юникод — это «уникальный код для каждого символа, независимо от платформы, программы или языка» (www.unicode.org).
Юникод использует 31 бит для кодирования символов. Первые 128 символов (коды 0-127) соответствуют таблице ASCII. Ниже перечислены основные алфавиты современных языков: Они находятся в первой части таблицы, и их коды не превышают 65 536 = 2 16 .
Стандарт Unicode описывает алфавиты всех известных языков, включая «мертвые» языки. Для языков с несколькими алфавитами или вариантами написания (например, японский и индийский) кодируются все варианты. Все математические и другие научные символы и даже некоторые придуманные языки (например, язык эльфов в трилогии Дж.Р.Р. Толкиена «Властелин колец») закодированы в Unicode.
В целом, современная версия Unicode позволяет кодировать более миллиона различных символов, но в действительности используется только 110 000 кодовых позиций.
В Юникоде существуют различные кодировки для представления символов в памяти компьютера.
Операционные системы семейства Windows используют UTF-16, кодируя все важные символы 2 байтами (16 бит), а редко используемые символы — 4 байтами.
В операционной системе Linux используется UTF-8, который может кодировать символы от 1 (символы ASCII) до 4 байт. Если важная часть текста состоит из цифр и латинских символов, это уменьшает размер файла до доли кодировки UTF-16.
Кодировки Unicode позволяют включать в один документ множество различных языков, но использование Unicode приводит к увеличению размера текстовых файлов.
14.3. Информационный объём текстового сообщения
Мы уже рассматривали этот вопрос в контексте алфавитного подхода к измерению информации.
Информационная емкость текстового сообщения — это количество битов (байтов, килобайтов, мегабайтов и т.д.), необходимых для записи этого сообщения с использованием заранее определенного метода двоичного кодирования.
Давайте подсчитаем текстовую информацию в современном 740-страничном словаре, если одна страница содержит в среднем 60 строк по 80 знаков каждая (включая пробелы).
Предположим, что используется кодировка «один символ — один байт». Количество символов во всем словаре одинаково:
80 — 60 — 740 = 3 552 000 .
Поэтому объем равен
3 552 000 байт = 3 468,75 Кбайт ? 3,39 Мбайт .
При использовании кодировки UTF-16 объем той же информации в байтах удваивается до 6,78 Мбайт.
ASCII как первый стандарт кодирования информации
Телетайп и терминал
В то же время были разработаны телепринтеры. Телепринтер — это система для передачи текстовой информации на расстояние. Два принтера и две клавиатуры (фактически электромеханические пишущие машинки) были соединены проводами. Текст, введенный на клавиатуре первого пользователя, печатался на принтере второго пользователя и наоборот. Например, в начале 1970-х годов была установлена телефонная связь между президентом США и советским руководством.
Телефонные аппараты также преобразуют текстовую информацию в определенные сигналы, которые передаются по кабелю. Двоичный код используется не всегда, например, в азбуке Морзе используются 3 символа — точка, тире и пробел. Телетайпные машины нуждаются в таблицах символов, которые отображают символы на кабельные сигналы. В этом случае таблицы символов для каждого телетайпа (пары соединенных телетайпов) могут быть разными в зависимости от того, какие задачи они решают. Например, язык и, следовательно, набор символов, передаваемых через устройство, могут быть разными. Для оптимизации телетайпа наиболее популярные (часто встречающиеся) символы кодировались самым коротким набором символов, так что набор символов мог быть разным в пределах одного языка.
Терминалы компьютерного доступа были разработаны на основе телефонных аппаратов. Такой телетайпный аппарат не отправлял сообщения второму пользователю, но информация вводилась в удаленный компьютер, который, обработав определенные команды, отправлял результат в виде ответного сообщения. Эта инновация позволила использовать вычислительную мощность компьютеров, которые в то время были очень дорогими, без физического доступа к самому компьютеру. Например, компьютер может находиться в отдельном вычислительном центре компании или института, а сотрудники в других филиалах или городах могут получить доступ к вычислительной мощности компьютеров через терминалы, установленные в их помещениях.
ASCII
Повсеместное распространение компьютеров и средств обмена текстовой информацией вызвало необходимость разработки единого стандарта кодирования для передачи и хранения информации. Такой стандарт был разработан в США в 1963 году. Таблица из 128 символов получила название ASCII — American Standard Code for the Exchange of Information.
Первые 32 символа ASCII являются управляющими символами. Они использовались, например, для управления телетайпом и для создания некоторых сложных персонажей. Например:
- символ Ø можно было получить так: печатаем O, затем с помощью управляющего кода BS (BackSpace) передвигаем печатную головку на один символ назад и печатаем символ /,
- символ à получался как a BS `
- символ Ç получался как C BS ,
С введением управляющих символов появилась возможность создавать новые символы как комбинацию существующих символов без необходимости вводить дополнительные таблицы символов.
Однако введение стандарта ASCII решило эту проблему только в англоязычных странах. В странах с другими шрифтами, такими как кириллица в СССР, проблема осталась.
Переход к Unicode
Рост интернета, увеличение количества компьютеров и уменьшение объема оперативной памяти означало, что проблемы, вызванные путаницей в кодировках, были компенсированы экономией оперативной памяти. Это было особенно заметно в Интернете, где текст, написанный на одном компьютере, должен был правильно отображаться на многих других устройствах. Это создавало огромные проблемы как для программистов, которым приходилось решать, какую кодировку использовать, так и для конечных пользователей, которые не имели доступа к интересующим их текстам.
В результате в октябре 1991 года была опубликована первая версия унифицированного набора символов под названием Unicode. Он содержал 7161 различных символов из 24 письменностей мира того времени.
Постепенно в Юникод добавлялись новые языки и символы. Например, версия 1.0.1 была обновлена в середине 1992 года и содержит более 20 000 идеограмм на китайском, японском и корейском языках. Текущая версия уже содержит более 143 000 символов.
Кодировки на основе Unicode
Юникод можно представить как огромную таблицу символов. В память компьютера записываются не сами символы, а числа из таблицы. Они могут быть написаны по-разному. По этой причине было разработано несколько кодировок на основе Unicode, которые отличаются способом записи номера символа Unicode в виде серии байтов. Они называются UTF — Unicode Transformation Format. Существуют кодировки фиксированной длины, например, UTF-32, где любое количество символов из таблицы Unicode занимает ровно 4 байта, и UTF-8, кодировка с переменной длиной байта, которая используется наиболее широко. Он позволяет кодировать символы таким образом, что наиболее распространенные символы занимают 1-2 байта, и только редкие символы занимают по 4 байта. Например, все символы в ASCII занимают ровно один байт, поэтому английский текст, записанный с помощью UTF-8, занимает столько же места, сколько и текст, записанный с помощью ASCII.
Unicode сегодня является самой важной системой кодирования, используемой всеми, кто имеет дело с компьютерами и текстом. Юникод позволяет использовать сотни тысяч символов и может быть представлен абсолютно одинаково на любом устройстве, от мобильного телефона до компьютера на космической станции.
Числовое кодирование текстовой информации
Каждый национальный язык имеет свой алфавит, состоящий из определенной последовательности идущих подряд букв, и, следовательно, имеет свой порядковый номер.
Каждой букве присваивается целое положительное число, называемое кодом символа. Этот код хранится в памяти компьютера, и когда он появляется на экране или на бумаге, он преобразуется в соответствующий символ. Помимо кода самих символов, в памяти компьютера также хранится информация о данных, закодированных в определенной области памяти. Это необходимо для того, чтобы различать информацию (числа и символы), находящуюся в памяти компьютера.
Специальные таблицы кодирования могут быть созданы путем сопоставления букв алфавита с их цифровыми кодами. Другими словами, мы можем сказать, что символы определенного алфавита имеют свои цифровые коды в соответствии с определенной кодировочной таблицей.
Однако, как мы знаем, в мире существует множество алфавитов (английский, русский, китайский и т.д.). Поэтому возникает вопрос о кодировании всех алфавитов, используемых в компьютере.
Чтобы ответить на этот вопрос, нам нужно вернуться в прошлое.
В 1960-х годах Американский национальный институт стандартов (ANSI) разработал специальную таблицу кодировки символов, которая с тех пор используется во всех операционных системах. Эта таблица называется ASCII (American Standard Code for Information Interchange).
В этой таблице представлен стандарт $7$-битного кодирования, который позволяет компьютеру записать любой символ в $7$-битную ячейку устройства памяти. Однако известно, что ячейка, состоящая из $7$ бит, может хранить $128$ различных состояний. В стандарте ASCII каждое из этих 128$ состояний соответствует букве, знаку препинания или специальному символу.
С развитием компьютерных технологий стало ясно, что $7$-битный стандарт кодирования довольно мал, поскольку 128$ состояний $7$-битной ячейки не могут закодировать буквы всех мировых письменностей.
Чтобы решить эту проблему, разработчики программного обеспечения начали создавать свои собственные стандарты кодирования 8-битного текста. Добавление дополнительного бита позволило расширить диапазон кодирования до 256$ символов. Чтобы избежать путаницы, первые $128$ символов в этих кодировках обычно соответствуют стандарту ASCII. Остальные $128$ представляют периферийные языковые особенности.
Поскольку известно, что существует множество национальных алфавитов, существует также множество вариантов расширенных кодов ASCII. Таким образом, для русского языка также существует несколько вариантов, наиболее распространенными из которых являются $$1251$ и Koi8-r. Большое количество таблиц кодирования приводит к трудностям. Например, мы отправляем письмо в одной кодировке, а получатель пытается прочитать его в другой. В результате получатель видит непонятную кашу и вынужден использовать другую таблицу кодировки, чтобы прочитать сообщение.
Другая проблема заключается в том, что некоторые языки имеют слишком много символов в своем алфавите, чтобы уложиться в допустимую кодировку байта $128$ — $255$.
Перевод текста в цифровой код.
Итак, учимся ли мы переводить текст в цифровой код? Кстати, на нашем сайте вы можете перевести любой текст в десятичный, шестнадцатеричный и двоичный код, воспользовавшись онлайн-калькулятором кодов.
Согласно компьютерной теории, каждый текст состоит из отдельных символов. К этим персонажам относятся: Буквы, цифры, мелкие знаки препинания, специальные символы («,№, (), () и т.д.) и пробелы между словами.
Также требуется большой объем фоновых знаний. Набор символов, используемый для записи текста, называется ALPHABETH.
Количество символов в алфавите означает его мощность.
Количество информации можно определить по формуле: N = 2b.
- N – та самая мощность ( множество символов),
- b – Бит ( вес взятого символа).
Алфавит, который будет содержать 256 символов, может содержать почти все необходимые символы. Эти алфавиты называются РЕАЛЬНЫМИ алфавитами.
Возьмем алфавит из 256 букв и заметим, что 256 = 28.
- 8 бит всегда называют 1 байт:
- 1 байт = 8 бит.
Если перевести каждый символ в двоичный код, то компьютерный текст будет занимать 1 байт.
Как текстовая информация может выглядеть в памяти компьютера?
Независимо от того, какой текст вводится на клавиатуре, на клавишах клавиатуры отображаются знакомые символы (цифры, буквы и т.д.). Они передаются в оперативную память компьютера только в виде двоичного кода. Двоичный код каждого символа выглядит как восьмизначное число, например, 00111111111111.
Поскольку байт является наименьшей адресуемой единицей памяти, а память адресует каждый символ индивидуально, преимущество такого кодирования очевидно. Однако 256 символов — это очень удобное число для любого вида символьной информации.
Естественно, возник вопрос: какой именно восьмизначный код принадлежит каждому символу? И как перевести текст в цифровой код?
Этот процесс является условным, и мы вольны находить различные способы кодирования символов. Каждый символ алфавита имеет номер от 0 до 255, и каждый номер кодируется от 00000000 до 11111111.
Таблица кодирования — это «контрольный лист», на котором буквы алфавита перечислены в соответствии с их порядковым номером. Для разных типов машин используются различные таблицы кодирования.
ASCII (или Asci) стал международным стандартом для персональных компьютеров. Таблица состоит из двух частей.
Таблица кода символов ASCII.
Первая половина предназначена для таблицы ASCII (первая половина стала стандартом).
Это называется принципом последовательного алфавитного кодирования, т.е. буквы (прописные и строчные) перечисляются в строгом алфавитном порядке, а цифры — в порядке возрастания.
Принцип последовательного кодирования применим и к русскому алфавиту.
В настоящее время существует пять систем кодирования, используемых для всего русского алфавита (KOI8-P, Windows, MS-DOS, Macintosh и ISO). Из-за множества кодировок и отсутствия единого стандарта при переводе русских текстов на компьютерный язык часто возникают недоразумения.
Одним из первых стандартов для кодирования русского алфавита на персональном компьютере является КОИ8 («Код для обмена информацией, 8-битный»). Эта кодировка использовалась в ряде компьютеров ECM в середине семидесятых годов, и начала использоваться в первых операционных системах UNIX с русской компиляцией в середине восьмидесятых.
В начале девяностых годов, так называемой эры, когда доминировала операционная система MS DOS, появилась система кодирования CP866 («CP» означает «кодовая страница»).
Компьютерный гигант APPLE ввел собственную систему кодировки алфавита MAC в своей инновационной системе (Mac OS).
Международная организация по стандартизации (ISO) определила другую систему кодирования алфавита под названием ISO 8859-5 в качестве стандарта для русского языка.
Сегодня наиболее распространенной алфавитной кодировкой является CP1251, которая используется в Microsoft Windows.
Со второй половины 1990-х годов проблема стандарта оцифровки текста для русского и других языков была решена введением стандартизированной системы под названием Unicode. Он представлен в шестнадцатеричной кодировке, что означает, что каждому символу отводится ровно два байта памяти. Естественно, такое кодирование удваивает потребность в памяти. Однако с помощью этой системы кодирования в электронный код можно преобразовать до 65536 символов.
Особенностью стандартной системы Unicode является то, что в ней можно разместить абсолютно любой алфавит, независимо от того, существует ли он, исчез или был изобретен заново. В конце концов, каждый алфавит, кроме системы Unicode, содержит множество математических, химических, музыкальных и общих символов.
Давайте воспользуемся таблицей ASCII, чтобы увидеть, как может выглядеть слово в памяти вашего компьютера.
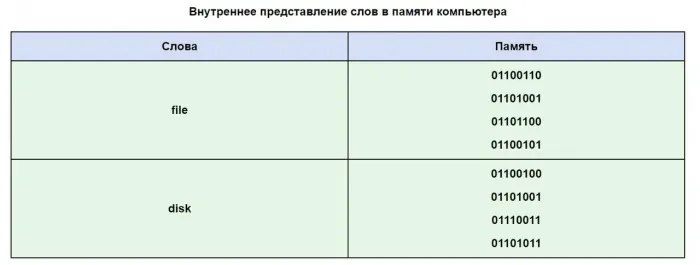
Очень часто бывает так, что ваш текст, написанный буквами русского алфавита, не читается, что связано с различными системами кодирования алфавита в компьютерах. Это очень распространенная проблема, которая встречается довольно часто.
Предпосылки Unicode
Я думаю, что мы должны начать с того времени, когда компьютеризация еще не была так развита и только начинала развиваться. В то время программисты и стандартизаторы не верили, что компьютеры и Интернет станут настолько популярными и распространенными. Именно тогда возникла необходимость в кодировании текста. Компьютер должен был хранить буквы в том же формате, но понимал только единицы и нули. Поэтому была разработана однобайтовая кодировка ASCII (возможно, не первая кодировка, но наиболее распространенная и представительная, поэтому она взята за основу). Что это такое? Каждый символ в этой кодировке кодируется 8 битами. Нетрудно подсчитать, что на этой основе кодировка может содержать 256 символов (восемь бит, нули или единицы 2 8 = 256).
Первые 7 бит (128 символов 2 7 = 128) этой кодировки были зарезервированы для латинских символов, управляющих символов (таких как переход на другую строку, табуляция и т.д.) и грамматических символов. Остальное было зарезервировано для национальных языков. Это означает, что первые 128 символов всегда одинаковы, а если вы хотите закодировать свой собственный язык, вы используете остальные. Так появился огромный зоопарк национальных кодировок. Теперь вы можете представить, что я создаю текстовый документ в России в стандартной кодировке Windows-1251 (русская кодировка, используемая в операционной системе Windows) и отправляю его кому-то в США. Также не поможет тот факт, что мой партнер знает русский язык, потому что, открыв мой документ на своем компьютере (в редакторе со стандартной кодировкой того же ASCII), он увидит не русские буквы, а кракозябры. Точнее, тогда эти части появятся в документе, который я пишу на английском языке без проблем, потому что первые 128 символов кодировки Windows 1251 и кодировки ASCII одинаковы, но там, где я написал русский текст, если я не исправлю его в своем редакторе, он будет в виде знаков препинания.
Я думаю, что проблема с национальными кодировками ясна. На самом деле, эти национальные кодировки очень, а интернет очень распространен, и все хотели писать на своем языке, и они не хотели, чтобы их язык был похож на крокодилов. У нас было два варианта: Мы можем определить кодировки для каждой страницы или создать общий набор символов для всех символов в мире. Победил второй вариант, поэтому была создана таблица символов Unicode.
Небольшой практикум ASCII
Это может показаться элементарным, но поскольку я решил объяснить все подробно, это необходимо.
Ниже приведена таблица символов ASCII:
Здесь у нас есть 3 колонки:
- номер символа в десятичном формате
- номер символа в шестнадцатиричном формате
- представление самого символа.
Unicode
Условия для создания общей таблицы для всех в мире персонажей, сортировка. Но теперь перейдем к самому столу. Unicode — это таблица (а не кодировка, т.е. таблица символов). Он содержит 1 114 112 цифр. Большинство этих мест еще не заняты людьми, поэтому нам вряд ли нужно расширять эту территорию.
Это общее пространство памяти разделено на 17 блоков по 65 536 символов в каждом. Каждый блок содержит свой набор символов. Блок ноль является основным блоком и содержит наиболее часто используемые символы всех современных алфавитов. Второй блок содержит символы из вымерших языков. Есть два блока для частного использования. Большинство блоков еще не заполнены.
Общая емкость символов Unicode составляет от 0 до 10FFFF (в шестнадцатеричном формате).
Символы записываются в шестнадцатеричном формате с префиксом «U+». Например, первый базовый блок содержит символы U+0000 — U+FFFFFF (от 0 до 65 535) и последний семнадцатый блок U+100000 — U+10FFFFFF (от 1 048 576 до 1 114 111).
Что ж, вместо зоопарка национальных кодов у нас теперь есть полная таблица всех символов, которые мы можем использовать. Но у него есть и свои недостатки. Если раньше каждый символ кодировался одним байтом, то теперь он может быть закодирован разным количеством байт. Например, для кодирования всех символов английского алфавита все равно достаточно одного байта, например, та же «o» в Unicode имеет номер U+006F, что является тем же номером, что и в ASCII — 6F в шестнадцатеричной системе и 111 в десятичной. Но чтобы закодировать символ «U+103D5» (который является древнеперсидским сотенным числом) — 103D5 в шестнадцатеричной системе и 66 517 в десятичной, то нам потребуется три байта.
Эта проблема должна быть решена с помощью кодировок Unicode, таких как UTF-8 и UTF-16. Мы рассмотрим их ниже.
UTF-8
UTF-8 — это кодировка Unicode переменной длины, которая может быть использована для представления любого символа Unicode.
Давайте поговорим подробнее о переменной длине, что она означает? Первое, что следует сказать, это то, что структурной (атомарной) единицей этого кодирования является байт. Тот факт, что кодировка имеет переменную длину, означает, что символ может быть закодирован разным количеством структурных единиц кодировки, т.е. разным количеством байт, например, латинские символы кодируются одним байтом, а кириллические символы — двумя байтами.
Немного отступлю от темы, надо написать про совместимость ASCII и UTF
Тот факт, что латинские символы и основные управляющие структуры, такие как дефисы, табуляции и т.д., кодируются одним байтом, делает кодировки utf совместимыми с кодировками ASCII. То есть, латинские символы и escape-коды находятся в одних и тех же местах в ASCII и UTF, и тот факт, что они кодируются одним байтом, обеспечивает эту совместимость.
Возьмем символ «o» из приведенного выше примера ASCII. Напомним, что в таблице символов ASCII он находится в позиции 111, в битовом формате это 01101111. В таблице Unicode этот символ — U+006F, в битовом формате это также 01101111. Поскольку UTF является кодировкой переменной длины, этот символ будет закодирован одним байтом. Это означает, что представление этого символа одинаково в обеих кодировках. То же самое справедливо для всего диапазона символов от 0 до 128. То есть, если ваш документ состоит из английского текста, вы не заметите никакой разницы, если откроете его в кодировках UTF-8 и UTF-16, а также в кодировке ASCII (обратите внимание, что в UTF-16 такие символы все равно кодируются двумя байтами, поэтому вы не заметите никакой разницы, если ваш редактор проигнорирует нулевые байты), и так далее, пока вы не будете работать с национальным алфавитом.
Давайте сравним, как фраза «Hello World» будет выглядеть в трех разных кодировках: Windows-1251 (русская кодировка), ISO-8859-1 (кодировка западноевропейских языков) и UTF-8 (кодировка Unicode). Суть этого примера в том, что предложение написано на двух языках. Давайте посмотрим, как это будет выглядеть в разных кодировках.
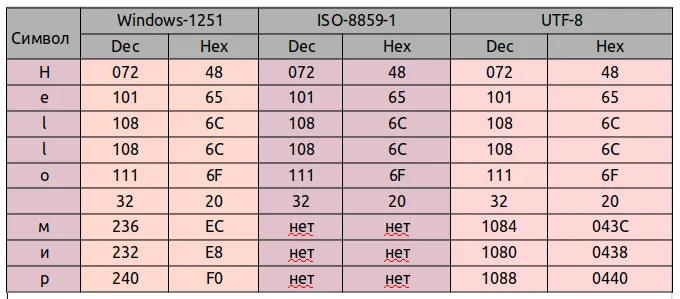
В кодировке ISO-8859-1 нет символов «m», «i» и «p».
Теперь давайте поработаем с кодировками и поймем, как преобразовать строку из одной кодировки в другую и что происходит, если преобразование неверно или не может быть выполнено из-за различий в кодировках.
Предположим, что предложение изначально было написано в кодировке Windows-1251. Начиная с таблицы выше, запишем это предложение в двоичной форме, в кодировке Windows-1251. Для этого нам просто нужно преобразовать десятичные или шестнадцатеричные символы (из таблицы выше) в двоичные.
01001000 01100101 01101100 01101111 00100000 11101100 11101000 11110000 Исключением является фраза «Hello World» в Windows-1251.
Предположим, у вас есть текстовый файл, но вы не знаете, какова кодировка этого текста. Вы предполагаете, что файл закодирован в ISO-8859-1, и открываете его в редакторе с этой кодировкой. Как я уже сказал, с некоторыми символами все в порядке, они находятся в этой кодировке и даже в тех же позициях, но вот с символами из слова «мир» все сложнее. Этих символов нет в данной кодировке, и вместо них в кодировке ISO 8859-1 присутствуют совсем другие символы. В частности, «m» — позиция 236, «i» — позиция 232. «р» — 240. И на этих местах в кодировке ISO-8859-1 находятся следующие символы Позиция 236 — символ «ì», 232 — «è», 240 — «ð».
Кодировки стандарта ASCII
| Определение: |
| Таблицы кодировки ASCII с основными символами (английский алфавит, цифры, знаки препинания, символы национальных алфавитов (разные в зависимости от региона), служебные символы) и длиной кода каждого символа mathn = 8/math бит. |
- ASCII7 — первая кодировка, пригодная для работы с текстом. Помимо маленьких букв английского алфавита и служебных символов, содержит большие буквы английского языка, цифры, знаки препинания и другие символы.
Кодировки ASCII (биты math8/math):
- ASCII — первая кодировка, в которой стало возможно использовать символы национальных алфавитов.
- КОИ8-R — первая русская кодировка. Символы кириллицы расположены не в алфавитном порядке. Их разместили в верхнюю половину таблицы так, чтобы позиции кириллических символов соответствовали их фонетическим аналогам в английском алфавите. Это значит, что даже при потере старшего бита каждого символа, например, при проходе через устаревший семибитный модем, текст остается «читаемым».
- CP866 — русская кодировка, использовавшаяся на компьютерах IBM в системе DOS.
- Windows-1251 — русская кодировка, использовавшаяся в русскоязычных версиях операционной системы Windows в начале 90-х годов. Кириллические символы идут в алфавитном порядке. Содержит все символы, встречающиеся в типографике обычного текста (кроме знака ударения).
Структурные свойства таблицы
Кодировки стандарта UNICODE
Unicode — это отраслевой стандарт, обеспечивающий цифровое представление символов мировых языков и специальных знаков.
Он был предложен в 1991 году некоммерческой организацией Unicode Consortium (Unicode Inc.). Использование этого стандарта позволяет кодировать очень большое количество символов из различных шрифтов. Стандарт состоит из двух частей: UCS (универсальный набор символов) и UTF (формат преобразования Юникода). Универсальный набор символов определяет взаимно-однозначное соответствие символов кодам — элементам кодового пространства, представляющим неотрицательные целые числа; семейство кодировок определяет механическое представление кодовой последовательности UCS.
Стандарт Unicode разделяет коды на несколько регионов. Кодовая область U+0000 — U+007F содержит символы набора ASCII с соответствующими им кодами. Есть также области для символов различных шрифтов, знаков препинания и технических символов. Кириллические символы разделены на диапазоны символов с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F. Некоторые коды зарезервированы для будущего использования.
Кодовое пространство
Хотя записи UTF-8 и UTF-32 позволяют кодировать позиционные коды вплоть до math2^/math math(2\147\483\648)/math, было решено использовать только math1\112\064/math для совместимости с UTF-16. Даже этого пока более чем достаточно: версия 6.0 имеет чуть меньше, чем math110\000/math цифр кода (math109\242/math для графики и math273/math для других символов).
Кодовое пространство разделено на уровни math17/math из math2^/math math(65\536)/math символов. Нулевой уровень называется базовым и содержит символы наиболее часто используемых сценариев. Первый уровень в основном используется для исторических шрифтов, второй — для редко используемых знаков китайской письменности, а третий — для архаичных китайских иероглифов. Самолеты math15/math и math16/math предназначены для частного использования.
Для символов в Юникоде используется символьная нотация «U+xxxxx» (для кодов math0000_..FFFF_/math ) или «U+xxxxx» (для кодов math10000_..FFFF_/math ) или «U+xxxxx» (для кодов math100000_..10FFFF_/math ), где xxx — шестнадцатеричные цифры. Например, символ «I» (U+044F) имеет код math044F_ = 1103_/math .
| Уровни Юникода | ||
|---|---|---|
| Самолет | Имя | Диапазон символов |
| Уровень 0 | Базовый уровень (BMP) | U+0000…U+FFFFFF |
| Уровень 1 | Дополнительный многоязычный уровень (SMP) | U+10000…U+1FFFFFF |
| Самолет 2 | Дополнительный идеографический уровень (SIP) | U+20000…U+2FFFFFF |
| Самолет 3-13 | Не назначено | U+30000…U+DFFFFFF |
| Уровень 14 | Дополнительный специальный уровень (SSP) | U+E0000…U+EFFFF |
| Самолеты 15-16 | Дополнительный уровень частного использования (S PUA A/B) | U+F0000…U+10FFFFFF |
Модифицирующие символы
Символы Юникода различаются на расширенные и нерасширенные. Нерасширенные символы отображаются, не занимая дополнительного места в строке символов. Расширенные символы — это, например, символы расширения. Расширенные и нерасширенные символы имеют свои собственные коды, но последний не может появляться один. Расширенные символы называются основными, а нерасширенные — комбинированными. Например, символ ‘Y’ (U+0419) может быть представлен как основной символ ‘Y’ (U+0418) и символ-модификатор ‘̆’ (U+0306).
Примеры
Если записать строку ‘hello world’ в файл exampleBOM и затем сделать шестнадцатеричный дамп, то можно увидеть, что разные символы кодируются разным количеством байт, например, английские буквы, пробелы, пунктуация и т.д. одним байтом, а русские буквы — двумя байтами.
Код на python
#!/usr/bin/env python #coding:utf-8 import codecs f = open('exampleBOM','w') b = u'hello world' f.write(codecs.BOM_UTF8) f.write(b.encode('utf-8')) f.close()
hex-дамп файла exampleBOM
| Символ | СПИСОК ЧАСТЕЙ | h | e | l | l | o | Космос | м | и | р | |||||
| Код UNICODE | EF | BB | BF | 68 | 65 | 6C | 6C | 6F | 20 | D0 | BC | D0 | B8 | D1 | 80 |
| Кодируется в UTF | 11101111 | 10111011 | 10111111 | 01101000 | 01100101 | 01101100 | 01101100 | 01101111 | 00100000 | 11010000 | 10111100 | 11010000 | 10111000 | 11010001 | 10000000 |