Что происходит во время декодирования (воспроизведения звука?).. Код преобразуется в электрические колебания, а выходное устройство — в колебания воздуха.
Краткое объяснение кодирования текстовой информации. Информатика
Кодирование текстовой информации — очень распространенное явление. Один и тот же текст может быть закодирован в разных форматах. Принято считать, что кодирование текстовой информации возникло с появлением компьютеров. Это и правда, и ложь. Кодирование в том виде, в котором мы его знаем, действительно появилось с приходом компьютеров. Однако люди боролись с самим процессом кодирования на протяжении сотен лет. По сути, само письмо — это способ кодирования человеческого дискурса для дальнейшего использования. Поэтому информация, которая нас окружает, никогда не представляется в чистом виде, поскольку она уже закодирована определенным образом. Однако сейчас это не является проблемой.
Наиболее распространенным способом кодирования текстовой информации является двоичная форма, которую используют все компьютеры, роботы, машины и т.д. Все закодировано в виде слов в двоичном представлении.
Сама технология двоичного представления информации зародилась задолго до появления первых компьютеров. Среди первых устройств, использовавших методы двоичного кодирования, был «Бодо» — телеграфный аппарат, который кодировал информацию в пяти битах двоичного представления. Суть кодирования заключалась в простой последовательности электрических импульсов.
В компьютерном мире это кодирование сопровождалось персонализацией самого компьютера. Другими словами, первые компьютеры не имели такой кодировки. Однако, как только компьютеры начали становиться «мейнстримом», внезапно возникла потребность в обработке больших объемов текстовой информации. Тенденция к обработке больших объемов текстовой информации сохраняется и в современных устройствах.
Двоичное кодирование в компьютерах иногда связано только с двумя символами ‘0’ и ‘1’, расположенными в определенном логическом порядке. Этот тип кодирования самого языка затем стал известен как механическое кодирование.
Кодирование текстовой информации и компьютеры
Если смотреть на текст компьютерным глазом, то в нем нет предложений, абзацев и заголовков. Это происходит потому, что весь текст состоит из отдельных букв. К таким символам относятся не только буквы, но и цифры, а также специальные символы (+, -, *, = и т.д.). Интересно, что даже вакуум, перевод строки и табличка являются отдельными компьютерными символами.
По референтным причинам. Существует уникальный язык программирования, в котором в качестве операторов используются только пробелы, знаки и линии. Практического применения этому языку нет, но он существует.
Текст вводится в компьютер с помощью клавиатуры, которую персонаж полностью понимает. Нажатие определенного символа посылает двоичное представление нажатой клавиши в основную память компьютера. Отдельные символы представлены в 8-битной кодировке. Например, буква ‘A’ имеет значение ‘11000000’. Символ может быть одним байтом или восемью битами. Используя это кодирование, с помощью простого расчета можно вычислить, что можно зашифровать 256 символов. Этого количества символов достаточно для кодирования текстовой информации.
Кодирование текстовой информации на вычислительном устройстве заключается в выполнении отдельных символов уникальных дробных значений от 0 до 255, или двоичных эквивалентов от 00000000 до 1111111111. .
Рассмотрим, как происходит процесс. Исходя из внешнего вида клавиатуры, нажимается нужный символ. Двоичное представление попадает в оперативную память компьютера, и когда компьютер выводит его на экран, происходит процесс декодирования, и на экране появляется знакомый символ.

Кодирование текстовой информации и таблицы кодировок
Таблицы кодирования — это место, где нам объясняют, что такое код. Все таблицы кодирования согласованы — это важно для различных устройств, так как не возникает путаницы между документами, закодированными по одной и той же таблице.
Сегодня существует множество различных таблиц кодирования. Это часто приводит к проблемам при передаче текстовых документов между устройствами. Поэтому, если текстовая информация закодирована в соответствии с таблицей, вы обнаружите, что она может быть декодирована в соответствии с этой таблицей. Если вы попытаетесь расшифровать по другой таблице, вы получите только один набор символов, которые вы не понимаете, но не читаемый текст.
Самые популярные таблицы кодирования:.
- ASCII,
- MS-DOS,
- ISO,
- Windows,
- КОИ8,
- CP866,
- Mac,
- CP 1251,
- Unicode,
- и др.
По мере развития программного обеспечения создавались новые стандарты для кодификации текста, но от старых стандартов было трудно уйти. Именно поэтому программное обеспечение было реализовано 50/50. Из-за расширенной сферы применения в каждом стандарте было 128 символов.
Трактовка понятий
Мысли человека выражаются в виде текста, состоящего из слов. Такое представление информации называется алфавитным, потому что основой языка является алфавит. Он рассматривается как конечное множество символов самой разной природы. Он используется для рисования сообщений.
Мы знаем, что цифры используются для представления чисел, а буквы — для представления звуков в письменной форме. Цифры и буквы можно назвать кодами. Одна и та же информация может быть закодирована разными способами. Например, китайские и японские иероглифы — это символы, используемые для кодирования букв и слов. Основой языка является алфавит, представляющий собой конечное множество точек (символов) любой природы, из которых строятся сообщения на данном языке. Другими словами, символизация информации — это описание объекта или явления с помощью символов алфавита. Сила алфавита понимается как символ количеств, составляющих этот алфавит. Он определяет количество возможных комбинаций (слов), которые могут составлять символ данного алфавита в соответствии с определенными правилами.
Обычно представление сообщения выбирается таким образом, чтобы его передача была максимально быстрой и надежной, а обработка — максимально удобной для получателя. Одно и то же сообщение может быть закодировано разными способами. Одной из систем кодирования является алфавит. Звуки также могут быть закодированы — такой системой кодирования является мемо. Помимо возможности хранения текстовой и акустической информации, изображения также могут быть закодированы. Если посмотреть на картину через увеличительное стекло, она покажется состоящей из точек. Координаты каждой точки могут быть сохранены в виде числа. Цвет каждой точки также может быть сохранен в виде числа. Эти числа могут храниться в памяти компьютера и передаваться на большие расстояния.
В случае шифрования данных необходимо знать правила кода рисунка (информационного контракта). Понятие кодирования относится к преобразованию сообщений с помощью комбинации символов с учетом кода. В общении люди используют русский или другие национальные языки. Во время речи коды передаются в звуке, а при написании сообщений — в буквах. Информация также передается водителю или пилоту с помощью световых сигналов и специальных символов или знаков.
Количество символов и графических представлений алфавита естественного языка исторически формируется и характеризуется особенностями языка (произносимыми звуками). Например, русский алфавит состоит из 33 символов, латинский — из 26, а китайский — из тысячи.
Основные методы кодирования информации в информатике включают арифметическое, символьное (текстовое) и графическое кодирование. Первый тип использует цифры, второй — символы из того же алфавита, что и оригинальный текст, а третий — изображения, рисунки или пиктограммы.
Двоичная методика
Современные компьютеры могут обрабатывать арифметическую, текстовую, графическую, аудио- и видеоинформацию. Компьютеры используют специальную систему двоичного кодирования для хранения, обработки и передачи информации. Его алфавит состоит только из двух точек «0» и «1». Это факт, что компьютеры могут обрабатывать и хранить только один тип представления данных — цифровой. Причина этого в том, что в цифровой электронике удобнее представлять информацию в виде последовательностей электрических импульсов. Техническое устройство, которое может адекватно различать две различные ситуации сигналов, легче построить, чем устройство, которое может адекватно различать пять или десять различных ситуаций. Поэтому поступающая на него информация должна быть преобразована в цифровой формат. Кодирование этой информации называется двоичным кодированием, которое лежит в основе всех компьютеров, смартфонов и т.д. вокруг нас.
В английском языке используются двоичные числа или представления битов. В одном бите — да или нет, белый или черный, ложный или истинный.
Двоичное кодирование привлекательно тем, что его технически легко применять. Электронные схемы для обработки двоичных кодов должны находиться только в одной из двух ситуаций: наличие сигнала/несигнала или высокого/низкого напряжения. Следовательно, каждый фрагмент информации кодируется в компьютере с помощью только двух цифр — 0 и 1.
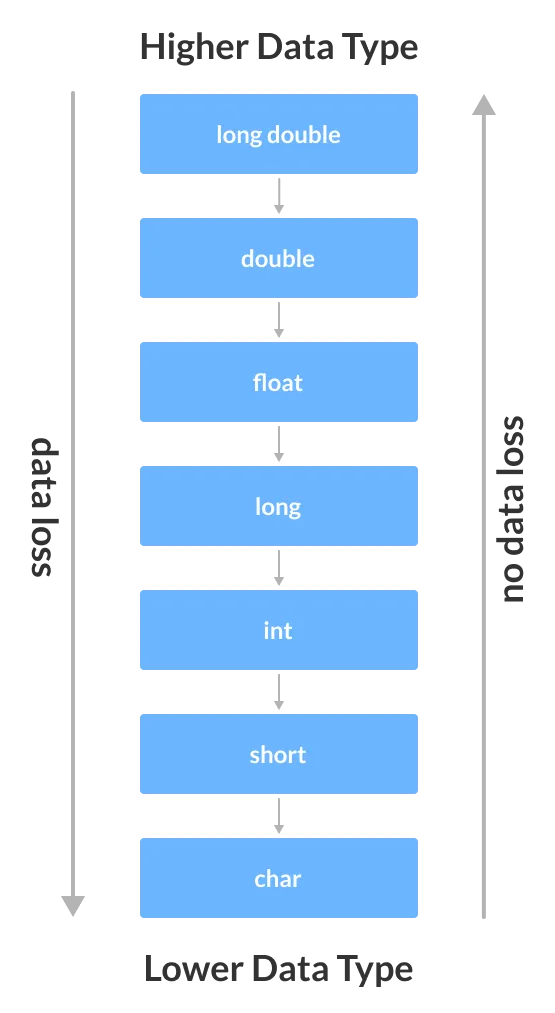
Таким образом, некоторые единицы информации — это биты и байты. Можно кодировать слегка два значения (0 или 1). Используя два бита, можно закодировать четыре значения: 00, 01, 10, 11. Приведенный выше пример показывает, что небольшое увеличение одного коэффициента 2 увеличивает количество значений, которые можно закодировать. Байт состоит из 8 битов и может кодировать 256 значений.
Традиционно один байт — это количество информации, используемое для кодирования символа. Именно поэтому в большинстве случаев текстовые символы, хранящиеся на компьютерах, соответствуют байтам памяти.
Помимо битов и байтов, используются и более крупные единицы информации.
- 1 бит ;
- 1 байт = 8 бит;
- 1 Кбайт = 2 10 байт = 1024 байт;
- 1 Мбайт = 2 10 Кбайт = 1024 Кбайт = 2 20 байт;
- 1 Гбайт = 2 10 Мбайт = 1024 Мбайт = 2 30 байт;
- 1 Тбайт = 2 10 Гбайт = 1024 Гбайт = 2 40 байт.
- 1 Пбайт = 2 10 Тбайт = 1024 Тбайт = 2 50 байт.
Для получения дополнительной информации о компьютерных системах см. статью Понимание информации. Компьютерные науки.
Текстовое значение
Кодирование и редактирование текстовой информации С 1960-х годов компьютеры все чаще используются для обработки текстовой информации. Компьютеры используют двоичное кодирование, то есть представление текста в виде последовательности нулей и единиц. Чтобы представить текст в виде цифр, каждая буква соединяется с цифрой. Концепция кодирования: символ — это код от 0 до 255 или двоичный код от 00000000 до 1111111111.
Текстовая информация состоит из букв, цифр и знаков препинания. Один байт достаточен для хранения 256 различных значений и может содержать буквенно-цифровые символы. Первые 128 символов (семь битов низкого класса) стандартизированы в кодировке ASCII (American Standard Code for Information Interchange). Суть кодирования заключается в том, что каждый символ устанавливается на двоичный код от 00000 до 11111111111111111111111111111 или десятичный код от 0 до 255.
В мировой практике для кодирования текста с помощью байтов используются различные стандарты. Наиболее распространенным, но не единственным типом кодирования является ASCII. Согласно этому стандарту, символы 0-32 соответствуют актам, а с 33-127 — латинским, пунктуационным и цифровым символам. Цены 128-255 используются для национального кодирования. Различные национальные коды имеют разные символы для одного и того же кода. Например, существует пять таблиц кодирования русских символов (Windows, MS -DOS, MAC, ISO, KOI -8). Поэтому текст, созданный в одной кодировке, не будет корректно отображаться в другой.
Первоначально коды ASCII содержали 7-битную информацию. Позже он был расширен до 8-битного кодирования (1 байт). По сравнению с 8-битным кодированием, 7-битное кодирование длится всего в два раза меньше. 2 7 = 128< 2 8 =256.
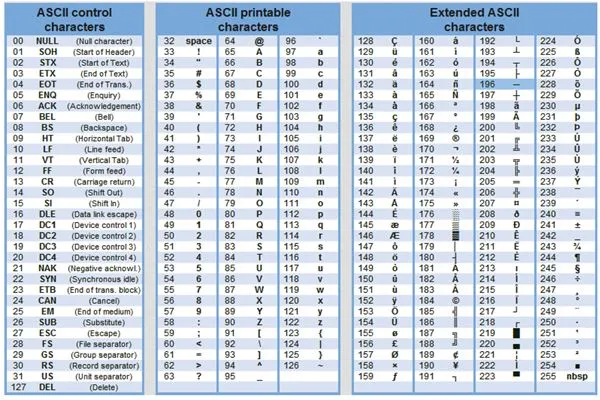
Таблица стандартных и альтернативных кодов ASCII
Код CP1251, используемый в настоящее время в операционных системах семейства Microsoft Windows, наиболее часто используется для кодирования кириллических символов. Во всех современных таблицах кодирования, помимо стандартных таблиц Unicode, для кодирования символов доступны восемь битов (8-бит).
В конце прошлого века появился новый международный Юникод, в котором каждый символ представлен двухбайтовым двоичным кодом. Эта модель является продолжением развития глобальной международной модели, которая решает проблемы совместимости национальных кодировок символов. Стандарт позволяет кодировать 65536 различных символов.
Если в предыдущих параграфах рассматривалась растровая графика (изображения состоят из множества пикселей и т.д.), то теперь пришло время поговорить о векторной графике.
Двоичный код
Наиболее распространенным методом кодирования информации является двоичное кодирование. Кодирование данных двоичным кодом используется во всех современных технологиях.
Двоичные коды — это последовательности нулей и единиц. Это универсальный способ представления всех типов информации (текст, изображения, аудио- и видеоданные). Преимущество использования двоичного кодирования информации заключается в том, что информацию, закодированную в двоичном коде, очень легко хранить, обрабатывать и передавать с одного электронного устройства на другое.
Для типа данных используется двоичное кодирование информации.
- двоичное кодирование текстовой информации заключается в присвоении буквенным, цифровым и другим обозначениям определенного кода. Он записывается в компьютерной памяти цепочкой из нулей и единиц. Порядок кодирования алфавита в двоичный код с помощью стандарта ASCII является наглядным примером;
- вид используемой графики влияет на то, каким образом производится двоичное кодирование графической информации;
- двоичное кодирование звуковой информации происходит после дискретизации звуковой волны и присвоения каждому компоненту соответствующего бинарной цепочки чисел;
- кодирование двоичным кодом видеоматериалов сочетает принципы работы со звуком и растровыми изображениями.
Обработка графических изображений
Кодирование текста, звука и графики осуществляется для качественного обмена, обработки и хранения. Кодирование различных типов информационных сообщений имеет свои особенности, но в целом приводит к их переводу в двоичную форму.
Схемы, книжные иллюстрации, диаграммы и рисунки. — Это примеры графических сообщений. Сегодня люди все чаще используют компьютерные технологии для работы с графическими данными.
Суть кодирования графической и звуковой информации заключается в преобразовании их из аналоговой формы в цифровую.
Кодирование графической информации — это процесс присвоения определенного кода значения каждому элементу изображения.
Кодирование графической информации зависит от того, как представлено изображение (растровое или векторное).
- Принцип кодирования графической информации растровым способом заключается в присвоении бинарного шифра пикселям (точкам), формирующим изображение. Код содержит сведения о цветовых оттенках каждой точки. Примером служат снимки, сделанные на цифровом фотоаппарате.
- Векторная кодировка осуществляется благодаря использованию математических функций. Компонентам векторных изображений (точкам, прямым и другим геометрическим фигурам) присваивается двоичная последовательность, определяющая разнообразные параметры. Такая графика зачастую применяется в типографии.
Источник.
Многие спросят: «Какой смысл кодировать графическую информацию, представленную в виде трехмерного изображения?». Дело в том, что работа с 3D данными сочетает в себе методы растрового и векторного кодирования.
Кодирование и обработка графической информации в различных форматах имеет свои преимущества и недостатки.
Метод координат
Данные могут передаваться через двоичные числа, содержащие графическое изображение, которое представляет собой набор точек. Для сопоставления чисел двоичного кода и точек используются координатные методы.
Метод уровневых координат основан на изучении свойств точек в горизонтальной системе координат ox и вертикальной оси oy. Точки имеют две координаты.
Если три взаимные вертикальные оси x, y и z проходят через первую, то используется метод пространственных координат. Положение одной точки в таком случае определяется тремя координатами.
Системы координат в пространстве