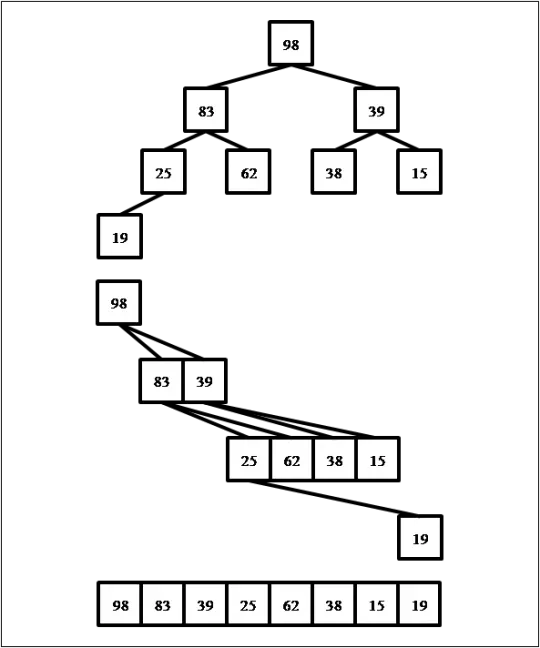
Дублирование данных действительно является проблемой, поскольку усложняет процесс CRUD. Например, при поиске в определенной таблице требуется дополнительное время на обработку дубликатов. Кроме того, когда пользователь обновляет твит, мы должны перезаписать все дубликаты.
Реляционные базы данных: объяснение для непрограммистов
Составление баз Данные являются сложным вопросом в разработке и некодировании. Студенты говорят нам, что особенно трудно понять тему данных. Мы говорим им, что такое реляционные базы данные, как их создавать, как их структурировать и почему лучше иметь с ними дело, чем жить без них.
В классическом программировании база Данные трудно понять и создать. Это цифры и ярлыки, это свой собственный язык, который вы должны знать.
Knowcode проще. База данных в noocode — это реальные, осязаемые и понятные данные. Это имена и фамилии, слова и тексты, картинки, даты, время, ценности и числа. Она написана в в базы Данные записываются в «исходном» виде — в виде букв и цифр.
Если открыть базу Если вы работаете с данными из продукта, который вы создали с помощью «НоуКод», все данные будут там. Столы будут стоять перед вами. Колонки будут иметь логичные и привычные названия, например, «Имя и фамилия клиента» или «Конец обслуживания» — с именами пользователей, предметов, вещей, событий, явлений. А строки таблицы будут содержать одни и те же данные — имя (Иван Иванов), цена (200 рублей). и так далее.
Что такое реляционная база данных
Как соединяются строки и столбцы в таблице – так в реляционных базах Данные в таблице связаны между собой.
Связь устанавливается с помощью одного свойства — оно называется ключом.
Рассмотрим пример.
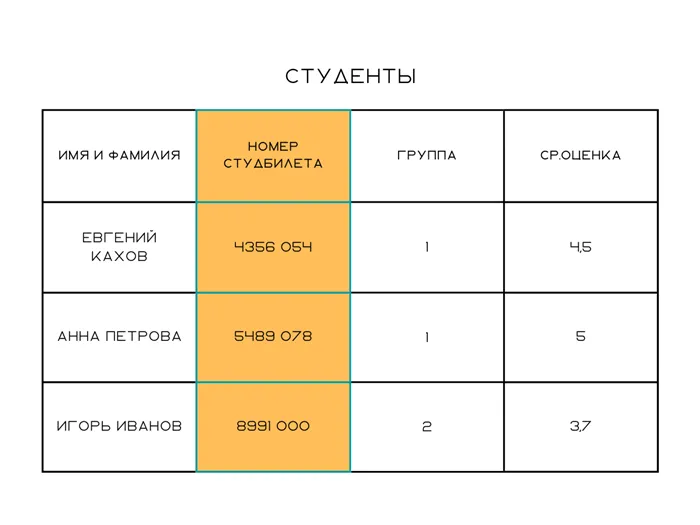
Мы делаем заявку для студентов университета. У нас есть база У нас есть стол со студентами, командами и профессорами. Есть таблица студентов, в которую мы вводим имя, фамилию, номер студента, группу и средний балл. Есть таблица с группами — для группы указан номер группы, количество студентов, сами студенты и куратор. В таком В случае таблицы с учениками, она связана с таблицей с группами по номеру группы. Номер группы является ключом для установления соединения.
Ключ может быть единицей данных, как в примере с номером группы, или может быть независимой единицей. Идентификатор можно использовать для создания ссылок на него. в базе — Разновидность искусственного ключа.
Это простейший пример ссылки в базах данных в ноакоде. Теперь поговорим о более сложных типах ссылок.
В этом типе данных одна строка информации связана со многими строками в другой таблице.
Опять же, пример со студентом. У стола с группами есть куратор. У каждой группы есть куратор, но куратор отвечает за многих студентов. Он помогает им решить проблемы со встречами, найти общежитие или уладить конфликт с преподавателем. Как правило, у студентов есть только один студенческий координатор, а у студенческого координатора много студентов.
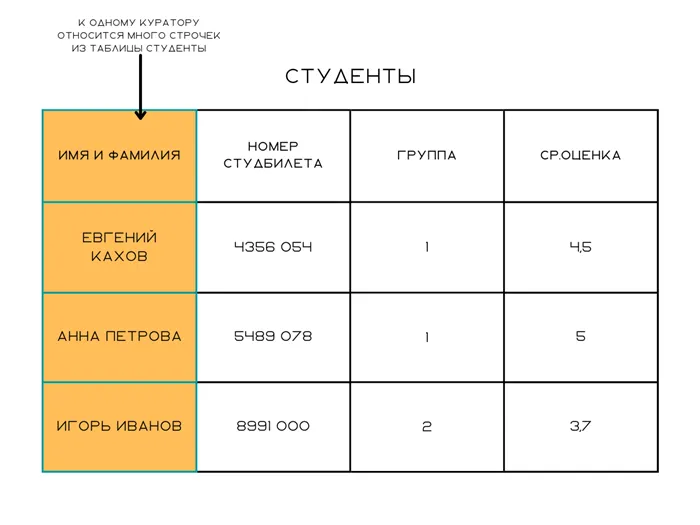
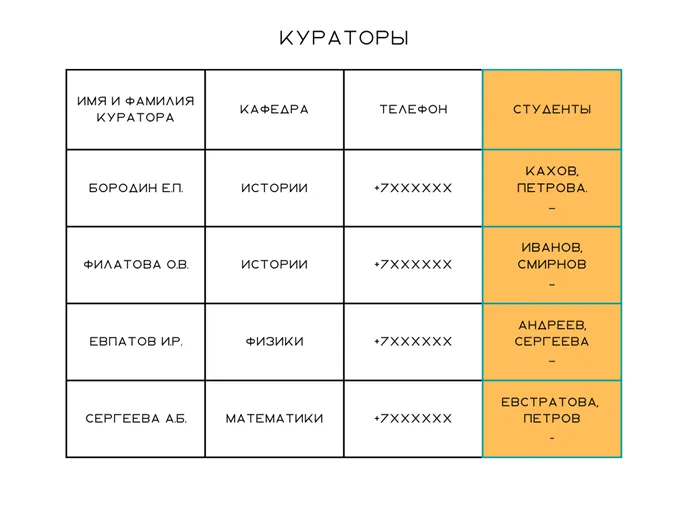
Примечания. Логичнее было бы объединить стол спонсора и стол студента, даже если у спонсора несколько групп. Однако мы хотели на примере показать, как выглядят эти отношения между двумя людьми. Это также Это можно сделать на примере группы: Для каждого студента есть только одна группа, но в каждой группе много студентов.
Дублирование данных действительно является проблемой, поскольку усложняет процесс CRUD. Например, при поиске в определенной таблице требуется дополнительное время на обработку дубликатов. Кроме того, когда пользователь обновляет твит, мы должны перезаписать все дубликаты.
Установление связи между таблицами
Давайте рассмотрим на примере адресной книги. базу Данные, которые можно реально использовать в профессиональной деятельности. Предположим, что люди в первой таблице являются пациентами больницы. Дополнительная информация о них может храниться в другой таблице. Столбцы второй таблицы могут быть названы таким как: пациент, врач, страховщик, баланс.
При извлечении информации из этих таблиц в соответствии с заданным критерием можно выполнить множество мощных операций, особенно если критерий включает связанную информацию из разных таблиц.
Предположим, доктор Халбен хочет получить номера телефонов всех своих пациентов. Чтобы получить эту информацию, ему необходимо связать таблицу, содержащую номера телефонов пациентов (адресная книга), с таблицей, определяющей его пациентов. В этом простом примере он может выполнить эту операцию мысленно и получить номера телефонов пациентов Грилле и Брока, тогда как в реальности эти таблицы могут быть гораздо больше и сложнее.
Программы, которые их обрабатывают реляционные базы Системы обработки данных предназначены для обработки больших и сложных наборов данных, которые наиболее часто встречаются в деловом мире общества. Даже если база больничные данные содержат десятки или тысячи имен (как это, вероятно, бывает в реальной жизни), простая команда SQL почти мгновенно предоставит доктору Халбену необходимую информацию.
Порядок строк произволен
Для максимальной гибкости в работе с данными строки таблицы по умолчанию никак не сортируются. Этот аспект отличает базу Данные отличаются от данных адресной книги. Строки в адресной книге обычно сортируются в алфавитном порядке. Один из мощных инструментов, который реляционными системами баз Данные — это то, что пользователи могут организовывать информацию по своему усмотрению.
Рассмотрим вторую таблицу. Содержащаяся в нем информация иногда удобно отсортирована по имени, иногда в порядке возрастания или убывания статуса счета, а иногда сгруппирована по врачам. Впечатляющее разнообразие возможных строк помешало бы пользователю гибко работать с данными, поэтому строки считаются неупорядоченными. По этой причине вы не можете просто сказать: «Меня интересует пятая строка таблицы». Независимо от порядка включения данных или других критериев, эта пятая строка по умолчанию не существует. Итак, строки таблицы рассматриваются в любом порядке.
Идентификация строк (первичный ключ)
По этой и многим другим причинам необходимо иметь столбец таблицы, который уникально идентифицирует каждую строку. Обычно этот столбец содержит, например, номер, присвоенный каждому пациенту. Конечно, можно использовать имя пациента для идентификации рядов, но можно также так, что есть несколько пациентов с именем Мэри Смит. В таком случае их нелегко различить. По этой причине обычно используются цифры. Этот единственный столбец (или группа столбцов), который используется для идентификации каждой строки и обеспечения того, чтобы все строки были разными, называется первичным ключом таблицы.
Первичный ключ таблицы является важным понятием в структуре данных. базы Структура данных. Это сердце системы данных: чтобы найти определенную строку в таблице, необходимо определить значение первичного ключа. Она также обеспечивает целостность данных. Если первичный ключ используется и поддерживается правильно, вы можете быть абсолютно уверены, что ни одна строка в таблице не пуста и что каждая строка отличается от других.
Реляционная база данных — это набор отношений, которые способны структурировать данные и обеспечить рациональное хранение и эффективное использование информационного материала.
Атрибуты отношений: первичные и внешние ключи
Теперь, когда отношения между объектами ясны, мы должны определить атрибуты, с помощью которых мы назначим объекты друг другу.
Такие атрибуты должны быть ячейками с уникальным содержимым. В каждой из наших таблиц есть только один столбец с уникальными данными.
В таблице Student у нас есть идентификатор студента, а в таблице Subject у нас есть идентификатор предмета. Эти ячейки называются первичными ключами.
Первичный ключ идентифицирует каждую строку в таблице.
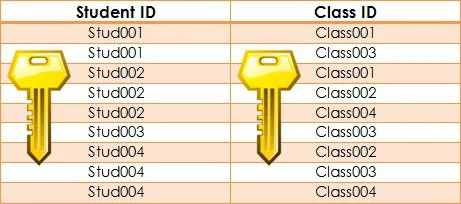
Чтобы создать связь, нам нужно сопоставить каждый первичный ключ с внешним ключом.
Внешний ключ должен представлять первичный ключ другой таблицы. В нашем случае внешний ключ может быть использован для создания специальной таблицы — таблицы перекрестных ссылок. Назовем эту таблицу таблицей записей.
Каждая строка этой таблицы записей будет связывать два внешних ключа:
- идентификатор студента (Student ID) – внешний ключ, ссылающийся на идентификатор студента в таблице студентов;
- идентификатор предмета (Class ID) – внешний ключ, ссылающийся на идентификатор предмета в таблице предметов.
Использование таблицы перекрёстных ссылок
Теперь, когда мы определили ключи и связи, мы можем заполнить таблицу перекрестных ссылок данными об объектах и их зависимостях.
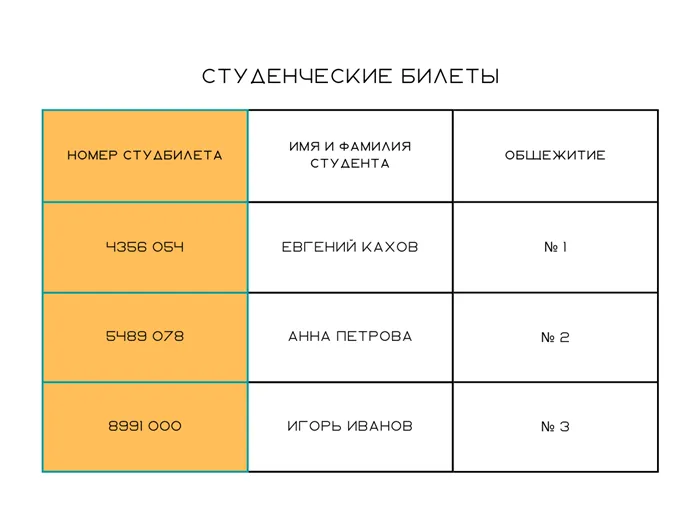
Каждая строка полученной таблицы однозначно определяется своим первичным ключом — идентификатором записи.
Помимо первичного ключа, таблица содержит еще два поля:
- внешний ключ Student ID ссылается на первичный ключ Student ID в таблице студентов;
- внешний ключ Class ID ссылается на первичный ключ Class ID в таблице предметов.
Заключение
В сегодняшней статье мы рассмотрели принципы организации. реляционных баз данных. Слово « реляционные «Отношения» можно определить как «характеризующиеся отношениями», от латинского слова «relatio» — «связь».
Отношения, о которых мы говорили, определяются отношениями между базы таблицы данных и проявляется в виде ограничений, накладываемых на допустимый диапазон значений связанных ячеек. Эти ограничения позволяют нормализовать данные, т.е. устранить ненужные повторения, и связать отдельные таблицы в единую запись.
Реляционная база данных — это набор отношений, которые способны структурировать данные и обеспечить рациональное хранение и эффективное использование информационного материала.
Что такое реляционная система управления базами данных?
Реляционные базы Он предназначен для управления большими объемами критически важных для бизнеса данных о клиентах. Однако, по мере увеличения объема данных, сложность баз данные становится все труднее хранить организованным, доступным и безопасным образом. Для решения этой проблемы используются системы управления. базамИ системы управления данными (DMS) служат именно этой цели: они добавляют к таблицам слой инструментов управления. к реляционным для создания слоя инструментов управления. Существуют различные структуры данных баз структуры данных и различные системы управления с разными уровнями организации, масштабируемости и реализации. Когда менеджеры работают с большими объемами структурированных и неструктурированных данных (Big Data) в режиме реального времени, системы управления должны реляционными базами системы управления данными помогают анализировать и обобщать данные для выявления заранее определенных взаимосвязей. Управление данными с помощью реляционных РСУБД приносят больше пользы организациям, поскольку они позволяют легче управлять данными, которые используются несколькими приложениями или находятся в разных местах.
Реляционные СУБД используют программное обеспечение, которое обеспечивает постоянный интерфейс между пользователями, приложениями и базой данные, чтобы пользователям было легче ориентироваться в них. Этот подход наиболее эффективен при работе с большими объемами данных, поскольку объем данных определяет необходимость согласованности для пользователей запросов. Выбор СУБД зависит от расположения данных, типа используемой архитектуры и предполагаемой масштабируемости.
Что такое реляционная модель базы данных?
Реляционная модель базы Системы управления данными обычно имеют следующие характеристики: они высокоструктурированы и поддерживают язык программирования SQL. Многие базы данных используют реляционную модели, поскольку они предназначены для организации данных и распознавания взаимосвязей между важными точками данных для облегчения классификации и поиска информации. Большинство реляционных Модели используют традиционную структуру таблиц со столбцами и строками: это эффективный, интуитивно понятный и гибкий способ хранения структурированных данных. Реляционная модель также решает проблему наличия множества произвольных структур данных в базах данных.
Масштаб моделей реляционных баз Данные могут быть самыми разными: от небольших настольных решений до крупных облачных систем. Такие модели используют базы Данные SQL или могут обрабатывать операторы SQL для выполнения запросов и обновлений. Реляционные модели определяются логической структурой данных (таблицы, индексы и представления) и отделены от физических структур хранения (физические файлы). Согласованность данных является наиболее важной характеристикой реляционных моделей баз данных, поскольку в таких базах данные сохраняются путем поддержания целостности данных между приложениями и экземплярами баз данных, которые также называемые экземпляры. В реляционной модели базы Экземпляры одних и тех же данных называются экземплярами. базы Копии данного набора данных всегда содержат одни и те же данные.
В реляционных базах Данные, предоставляемые в облаке, автоматически настраиваются на высокую доступность, т.е. данные реплицируются или копируются между несколькими участниками, при этом участники находятся в разных зонах доступности. Таким образом, данные остаются доступными даже в случае отключения центра обработки данных.

Большие данные и реляционные базы данных
Традиционные реляционные базы Центры обработки данных предназначены для управления большими объемами структурированных данных. Это причина реляционные базы Центры обработки данных идеально подходят для структурированных Больших Данных: они основаны на SQL и могут использовать СУБД для управления данными. Однако в больших и более сложных наборах Больших Данных разнообразие увеличивается, что означает, что данные из новых источников становятся менее структурированными. Поэтому часто необходимо использовать нереляционные базы Языки NoSQL используются для работы с неструктурированными и полуструктурированными данными.
В реляционных базах NoSQL используют язык SQL для организации и запроса данных во взаимосвязанных структурах таблиц.
Система управления реляционными базами данных (реляционная СУБД) использует программное обеспечение для управления данными. в базе данных.
Структура этого типа отношений похожа на предыдущий тип, но работает в обратном порядке — есть первичная таблица и вторичная таблица. Здесь отношения строятся от наиболее важной таблицы к наименее важной.
Шаг 4: Объединяем таблицы на основе ключей
Итак, В результате наших действий таблица 1 была разделена на три части: Последователи (Таблица 2), Твиты (Таблица 4), Пользователи (Таблица 5). Все дубликаты были удалены. Чтобы в будущем из этой структуры можно было легко извлекать данные, независимые таблицы должны быть связаны специальными отношениями, которые подскажут нам, какой пользователь владеет каким твитом и кто является каким подписчиком.
Чтобы установить связи между записями, необходимо ввести уникальный идентификатор, называемый первичным ключом.
В целом, мы уже сделали это в таблицах 4 и 5. В таблице «users» первичным ключом является столбец «username», поскольку имя пользователя должно быть уникальным значением и не может повторяться. В таблице «твиты» мы используем этот ключ для указания связи между пользователем и твитом. Столбец username в таблице tweets называется внешним ключом.
Если вы когда-либо работали с с базами данных, вы можете спросить себя: можем ли мы использовать столбец username в качестве первичного ключа?
С одной стороны, это может упростить процесс поиска, поскольку мы не используем числовой идентификатор. Но что, если пользователь хочет изменить свое имя пользователя? Это может вызвать множество проблем. Лучший способ избежать этой ситуации — использовать числовые идентификаторы. Это полностью зависит от вашей системы. Если вы разрешаете пользователям менять свои имена, лучше всего использовать числовое поле ID с автоинкрементом в качестве первичного ключа. В противном случае для этой роли достаточно столбца «имя пользователя». Я оставлю все как есть.
Давайте посмотрим на таблицу твитов (Таблица 4). Первичный ключ должен быть уникальным для каждой строки. Какой столбец этой таблицы мы можем выбрать для этой роли? Колонка «created_at» не будет работать, потому что в принципе 2 разных пользователя могут сделать запись в одно и то же время. Аналогичная ситуация и с колонкой «текст»: два разных пользователя могут создать твит с текстом «Hello World». Столбец «имя пользователя» в этой таблице является внешним ключом, который указывает на связь между пользователем и твитом. Итак, Поскольку все возможные варианты нам не подходят, лучшим решением будет добавить столбец id, который будет первичным ключом для этой таблицы.
Таблица 6: Твиты с колонкой id
| id | Текст | созданная_дата | Имя пользователя |
|---|---|---|---|
| 1 | «Что вы думаете о #социальных #кампаниях в #США? Являются ли они хорошей покупкой и сегодня? Есть ли у вас #базы данных?» | «Tue, 12 Feb 2013 08:43:09 +0000» | «_DreamLead» |
| 2 | «Билл Гейтс обсуждает базы данных, свободное программное обеспечение на Reddit http://t.co/ShX4hZlA #billgates #databases» | «Tue, 12 Feb 2013 07:31:06 +0000» | «ГуннарСваландер». |
| 3 | «RT @KirkDBorne: Readings in #Databases: отличный список литературы, много категорий: http://t.co/S6RBUNxq via @rxin Увлекательно». | «Tue, 12 Feb 2013 07:30:24 +0000» | «GEsoftware». |
| 4 | «RT @tisakovich: @NimbusData сегодня на конференции @Barclays Big Data в Сан-Франциско, рассказывая о #виртуализации, #базах данных и #флэш-хранилищах». | «Tue, 12 Feb 2013 06:58:22 +0000» | «adrianburch» |
| 5 | «http://t.co/D3KOJIvF статья о Madden 2013 с использованием ИИ для предсказания суперкубка #базы данных #bus311» | «Tue, 12 Feb 2013 05:29:41 +0000» | «AndyRyder5» |
| 6 | «http://t.co/rBhBXjma статья о настройках конфиденциальности и Facebook #базы данных #bus311» | «Tue, 12 Feb 2013 05:24:17 +0000» | «AndyRyder5» |
| 7 | «#BUS311 NCFPD Университета Миннесоты создает #базы данных для предотвращения «пищевого мошенничества». http://t.co/0LsAbKqJ». | «Tue, 12 Feb 2013 01:49:19 +0000» | «Brett_Englebert». |
| 8 | «#BUS311 Компании могут защитить свои #производственные базы данных, но что насчет их резервных файлов? http://t.co/okJjV3Bm». | «Tue, 12 Feb 2013 01:31:52 +0000» | «Brett_Englebert». |
| 9 | «Генеральный директор @NimbusData @tisakovich @BarclaysOnline Big Data Conference в Сан-Франциско сегодня, говорит о #виртуализации, #базах данных и #флэш-хранилищах». | «Mon, 11 Feb 2013 23:15:05 +0000» | «NimbusData». |
| 10 | «Не забудьте подписаться на БЕСПЛАТНЫЙ отчет в эту пятницу: #Databases, #BI, & #Sharepoint: что вам нужно знать! http://t.co/Ijrqrz29». | «Mon, 11 Feb 2013 22:15:37 +0000» | «ССВУГорг» |
Системы Управления Базами Данных
Теперь, когда у нас есть реляционная БД, как мы можем их реализовать? Для этого мы можем использовать системы управления базамИ системы управления данными (СУБД). Существует широкий спектр таких программ, как оплачиваемых, так и неоплачиваемых. так И бесплатно. Платные базы данных включают Oracle Database, IBM DB2 и Microsoft SQL Server. Бесплатно: MySQL, SQLite и PostgreSQL.
Чаще всего различные компании используют MySQL, и Twitter не является исключением.
SQLite чаще всего используется при разработке приложений для iOS и Android, в которых хранятся различные виды конфиденциальной информации. Google Chrome использует SQLite для хранения истории просмотров, файлов cookie и изображений.
PostgreSQL используется реже. Для этого существует полезное расширение PostGIS, которое делает эту СУБД пригодной для хранения геолокационных данных. OpenStreetMap, например, использует PostgreSQL.
Язык структурированных запросов (SQL)
После того как вы выбрали и установили подходящую для вас РСУБД, следующим шагом будет создание таблиц и управление данными. Для этого мы можем использовать специальный язык SQL.
Создание базы данных разработки.
- Создание БД с названием «development»
- Создание таблицы «users»
При создании полей нам необходимо указать тип хранимой информации и ее размер. Колонки «full_name» и «username» будут иметь тип VARCHAR, который предназначен для хранения строк. Размер составляет 100 символов. Список всех типов можно найти здесь.
SQL очень похож на человеческий язык (английский). Каждый SQL имеет свои особенности и отличия в каждой базе данных, но в целом все варианты SQL похожи друг на друга.
В этом уроке мы описали процесс создания реляционной база данных, которая принимает набор данных и разделяет их на таблицы в соответствии с определенным реляционной Модель. Мы также провели быстрый тест существующей СУБД и языка SQL.
В данном концептуальном документе представлена история реляционной модели, как данные организованы в реляционными Системы и примеры того, как она используется в настоящее время.
Особенности реляционных БД
Базы данных используются для организации хранения данных. Структура реляционной базы данные полностью определяются списком имен полей с их типами и свойствами. Все записи имеют одинаковые поля, но отображают разные свойства объекта. Аналог реляционной базы данных представляет собой двумерную таблицу. Характеристики записи базы данных:
- Уникальное имя для каждой таблицы.
- Фиксированное число полей.
- На пересечении строки и столбца всегда есть только одно значение.
- Записи отличаются друг от друга хотя бы одним значением элемента.
- Полям присваиваются индивидуальные имена.
- В каждый из столбцов необходимо вставлять однородные данные: целые числа, даты, суммы, имена или фамилии, названия предметов.
В большинстве случаев реляционная база данных не ограничивается одной таблицей. Обычно создается несколько таблиц со связанной информацией. Это позволяет выполнять более сложные операции с данными. Таблицы в базе данных более сложные. реляционной базы данных должны отвечать требованиям концепции нормализации отношений, т.е. они должны формулировать ограничения, позволяющие избежать повторений и обеспечить согласованность хранимой информации. Создадим таблицу «Аренда» со следующими полями: Код клиента, имя, тип устройства, дата выдачи, оплата, дата возврата. Такая организация хранения информации имеет ряд недостатков:
- дублирование информации (вид устройства повторяется для разных клиентов), что увеличивает объём БД;
- для обновления информации требуется обрабатывать каждую запись.
Для устранения этих недостатков требуется нормализация путем разбиения данных на различные таблицы.
Связывание таблиц
Для любой таблицы реляционной База данных определяет первичный ключ — поле или комбинацию полей, которые определяют каждую запись. Внешний ключ или вторичный ключ — это одно или несколько полей, которые ссылаются на поле первичного ключа другой таблицы.

Составной ключ называется так, потому что она создается несколькими полями. При формировании составных ключей не рекомендуется включать поля, значения которых точно определяют запись. Например, не следует формировать ключ, включающий поля «номер паспорта» и «код клиента» вместе, поскольку эти два атрибута однозначно определяют запись. Поля с повторяющимися значениями в таблице также не должны быть частью ключа. Можно найти только одну запись со значением ключа.
Ячейка — это наименьший строительный блок, который определяет конкретное значение соответствующего поля. Таблицы связаны друг с другом, поэтому данные из нескольких таблиц могут быть выбраны одновременно. Связь устанавливается, если они содержат одинаковые поля. Типы ссылок:
- один к одному;
- один ко многим;
- многие ко многим.
Связи «один к одному» встречаются довольно редко. Связи «один-ко-многим» встречаются чаще, например, кассир продает много билетов. Также часто встречаются связи «многие-ко-многим». Например, студент, который посещает много занятий. Соединения «многие-ко-многим» не могут быть оплачены напрямую. Чтобы создать взаимосвязь, необходимо сопоставить каждый первичный ключ с внешним ключом, который является первичным ключом другой таблицы. Реляционные системы базируются на теории реляционной Модели с тремя аспектами:
- структурный — данные в базе рассматриваются как набор отношений, то есть упорядоченных пар, составленных из заголовка и полей;
- целостности — состоит в проверке правильности согласования данных при обновлении;
- обработки — использование операторов манипулирования таблицами, таких как реляционная алгебра и реляционное исчисление, которые генерируют новые таблицы на основании уже имеющихся.
Создание и использование базы данных управляется административными системами базами данных (СУБД).
Под их контролем:
- производится добавление, определение, удаление и поиск записей;
- изменяются значения полей.
Для выполнения этих операций организуются запросы. Результатом запросов являются либо изменения в таблицах, либо получение таблицы данных. Соблюдается принцип информационной безопасности. Для реляционной Основным языком управления базами данных является SQL.
Стадии и пример проектирования хранилища
В начале творения базы, программист создает представление объектов манипуляции и их отношений на основе реляционной база данных (таблицы, поля, записи). Проектирование проходит несколько этапов:

- Первая стадия — это анализ требований. Разработчик должен разрешить главные проблемы: какие элементы данных будут содержаться, как и кто должен к ним обращаться.
- В следующей стадии проектируется логическая структура БД.
- В завершающей стадии проектирования логическая структура БД трансформируется в физическую. Элементы данных определяются как табличные столбцы.
Преимущества этой модели данных в том, что информация отображается в удобном для пользователя формате, а для манипуляций используется разработанный математический аппарат.
Примером реляционной базы Модель данных может служить в качестве плана для оптимизации работы станции проката. Следующие процессы должны быть автоматизированы такие Автоматизация процессов: Регистрация клиентов, регистрация запасов, аренда запасов, отслеживание даты выдачи, даты возврата, оплаты, получение информации по этим пунктам, формирование отчета о задержках. Реляционная база данных состоит из трех взаимосвязанных таблиц.
Используя имеющиеся данные, определите взаимосвязи и объекты этих взаимосвязей. Объектами будут клиенты и оборудование. Отношения между ними заключаются в том, что каждый клиент может взять одно или несколько устройств.
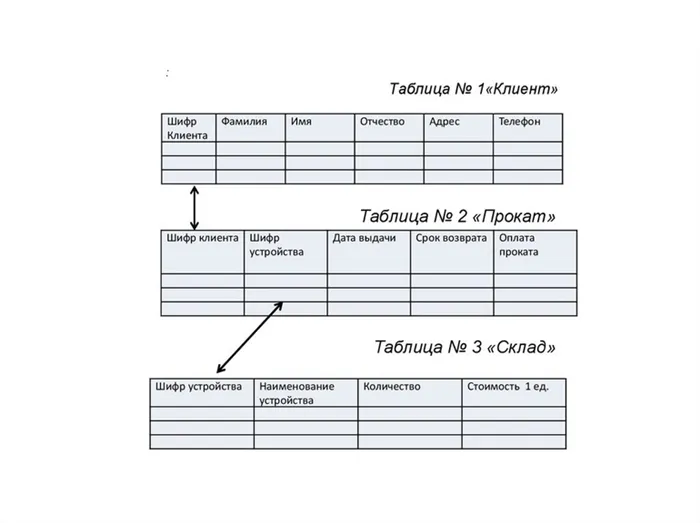
Атрибуты для связи объектов друг с другом должны быть ячейками с уникальным содержимым. В каждой таблице есть поле с уникальными данными. Номер 1 «Клиент» будет ключом клиента, а номер 3 «Склад» — ключом подразделения. Это будут первичные ключи. В каждой строке таблицы «Hire» будут связаны два внешних ключа:
- Шифр Клиента — foreign key, ссылающийся на primary key в таблице «Клиент».
- Шифр устройства — foreign key, ссылающийся на первичный ключ в таблице «Склад».
Приведенных выше абзацев достаточно, чтобы дать вам представление о теоретической основе организации реляционных баз Данные. Однако сухой теории недостаточно, чтобы действительно понять предмет. Поэтому в оставшейся части статьи мы попытаемся разработать базу Данные для небольшого приложения.
Как реляционные базы данных структурируют данные
Теперь, когда у вас есть общее представление об истории реляционной модели, давайте теперь подробнее рассмотрим, как эта модель структурирует данные.
Наиболее важные элементы реляционной Отношение — это набор кортежей или строк в таблице, где каждый кортеж имеет набор атрибутов или столбцов:
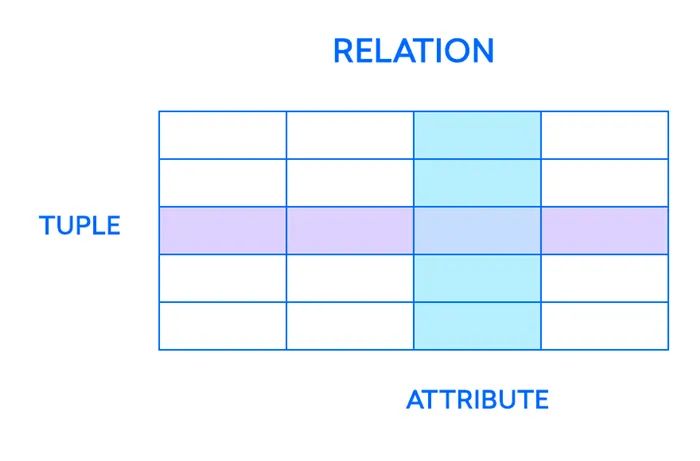
Колонна является самой маленькой организационной структурой реляционной базы данные, представляющие различные ячейки, которые определяют записи в таблице. Отсюда и более формальное название «атрибуты». Каждый кортеж можно рассматривать как уникальный экземпляр чего-то, что может существовать в таблице: категория людей, объектов, событий или ассоциаций. Это могут быть сотрудники компании, продажи в интернет-магазине или результаты лабораторных исследований. Например, в таблице, содержащей данные о занятости учителей в школе, кортежи могут иметь следующий вид. такие Атрибуты, такие как имя, предметы, дата начала работы и т.д.
При создании столбцов вы указываете тип данных, который определяет записи, которые могут быть введены в этот столбец. РСУБД часто используют свои собственные типы данных, которые не являются непосредственно взаимозаменяемыми с аналогичными типами данных в других системах. К распространенным типам данных относятся даты, строки, целые числа и логические значения.
В реляционной Каждая модель таблицы содержит как минимум один столбец, который может быть использован для уникальной идентификации каждой строки. Это называется первичным ключом. Это важно, поскольку пользователям не нужно знать, где физически хранятся данные на компьютере. Ваша СУБД может отслеживать каждую запись и возвращать ее в соответствии с ее назначением. Это, в свою очередь, означает, что записи не имеют определенного логического порядка, и пользователи могут возвращать данные в любом порядке или с любыми фильтрами.
Если вы хотите связать две таблицы вместе, вы можете сделать это с помощью внешнего ключа. Внешний ключ — это, по сути, копия первичного ключа одной таблицы («таблица-предшественник»), вставленная в столбец другой таблицы («таблица-преемник»). В следующем примере показана связь между двумя таблицами: Один используется для записи информации о сотрудниках компании, а другой — для отслеживания продаж компании. В этом примере первичный ключ таблицы EMPLOYEES используется в качестве внешнего ключа таблицы SALES:
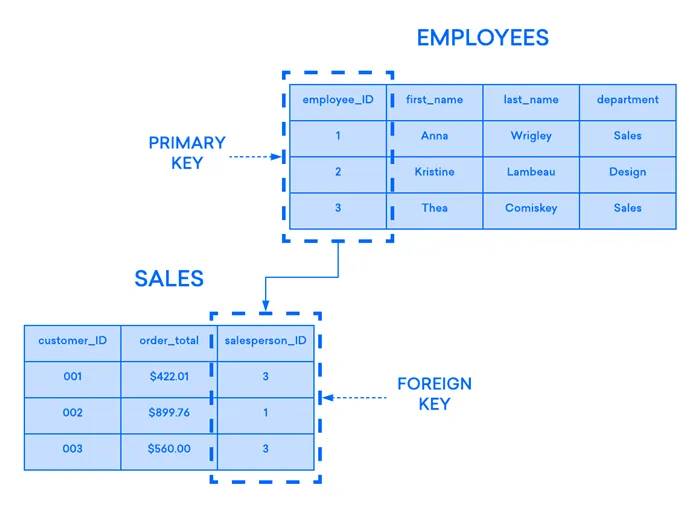
Если вы попытаетесь добавить запись в таблицу-предок, а значение, введенное в столбец внешнего ключа, не присутствует в первичном ключе таблицы-предка, запись будет недействительной. Это помогает поддерживать целостность слоя отношений, так как строки в обеих таблицах всегда правильно связаны.
Структурные элементы реляционной Модели помогают хранить данные в структурированном виде, но хранение важно только в том случае, если вы можете извлечь данные. Чтобы получить информацию из РСУБД, можно создать запрос, который представляет собой структурированный запрос на набор информации. Как упоминалось ранее, большинство реляционных баз данных использует язык SQL для управления данными и отправки запросов. SQL позволяет фильтровать и обрабатывать результаты, используя различные предложения, предикаты и выражения для управления данными, которые появляются в результате.
Преимущества и ограничения реляционных баз данных
Учитывая организационную структуру, стоящую за реляционных баз Данные, давайте рассмотрим некоторые их преимущества и недостатки.
Сегодня как SQL, так и базы Данные, используемые в нем, несколько отличаются от от реляционной Модель Кодда. Например, модель Кодда определяет, что каждая строка в таблице должна быть уникальной, и по практическим соображениям большинство современных реляционных баз Данные допускают дублирование строк. Есть и те, кто не верит, что базы Данные на основе SQL как истинные реляционными базами данные, если они не соответствуют всем критериям реляционной модель в соответствии с версией Кодда. На практике, однако, любая СУБД, использующая SQL и каким-либо образом связанная с реляционной модель, обусловлена к реляционным системам управления базами данных.
Хотя популярность реляционных баз данных быстро растет, некоторые из недостатков реляционной модели становилось очевидным по мере увеличения стоимости и объема хранимых данных. Например, трудно масштабировать реляционную базу данные по горизонтали. Горизонтальное масштабирование — это добавление большего количества машин к существующему стеку для распределения нагрузки, увеличения трафика и ускорения обработки. Это часто сравнивают с вертикальным масштабированием, когда аппаратное обеспечение существующего сервера модернизируется, обычно путем добавления оперативной памяти или памяти процессора.
Реляционную базу Его трудно масштабировать по горизонтали, поскольку он предназначен для обеспечения целостности, т.е. чтобы клиенты отправляли свои запросы на один и тот же сервер. же базу Данные всегда получают одни и те же. Когда вы масштабируете реляционную базу горизонтально по всем машинам, трудно обеспечить целостность, поскольку клиенты могут передавать данные только одному узлу, а не всем узлам. Скорее всего, между первой записью и обновлением других узлов для отражения изменений произойдет задержка, что приведет к нарушению целостности данных между узлами.
Еще одно ограничение, существующее в РСУБД, заключается в том, что. что реляционная Модель предназначена для управления структурированными данными или данными, которые соответствуют заранее определенному типу данных или, по крайней мере, предварительно организованы определенным образом. Однако с распространением персональных компьютеров и развитием Интернета в начале 1990-х годов появились неструктурированные данные., такие например, электронные письма, фотографии, видео и т.д.
Однако все это не означает, что что реляционные базы данные бесполезны. Напротив, более 40 лет спустя, реляционная эта модель все еще является доминирующей основой для управления данными. Распространенность и продолжительность жизни реляционных баз данных показывает, что это зрелая технология, что само по себе является большим преимуществом. Существует множество приложений, которые можно использовать для работы с с реляционной моделью, а также многие карьерные менеджеры баз данных, которые являются экспертами, когда дело доходит до до реляционных баз данные. Существует также широкий спектр печатных и онлайн-ресурсов для тех, кто хочет начать работу. с реляционными базами данных.
Еще одно преимущество реляционных баз заключается в том, что почти все РСУБД поддерживают транзакции. Транзакция состоит из одного или нескольких отдельных операторов SQL, которые выполняются последовательно как единое целое. Транзакции — это подход «все или ничего», означающий, что все операторы SQL в транзакции должны быть действительными. В противном случае вся транзакция завершится неудачей. Это очень полезно для обеспечения целостности данных, когда изменения вносятся в несколько строк или таблиц.
Заключение
Благодаря гибкости и концепции поддержания целостности данных, через пятьдесят лет после введения такого замысла, реляционные базы они остаются основным средством управления и хранения данных. Даже при растущем разнообразии баз Данные NoSQL, понимание реляционной модель и то, как она работает с РСУБД, важно для всех, кто хочет разрабатывать приложения, использующие данные.
Если вы хотите узнать больше о различных популярных РСУБД с открытым исходным кодом, мы рекомендуем вам прочитать наше сравнение различных реляционных баз Данные из открытых источников. Если вы хотите узнать больше о о базах В целом, мы рекомендуем вам просмотреть всю нашу библиотеку материалов. о базах данных.
Want to learn more? Join the DigitalOcean Community!
Присоединяйтесь к сообществу DigitalOcean, насчитывающему более миллиона разработчиков, бесплатно! Получайте помощь и делитесь знаниями в разделе вопросов и ответов, находите учебники и инструменты, которые помогут вам расти как разработчику и расширять свой проект или бизнес, а также подписывайтесь на интересующие вас темы.